Summer vacation is here. For our family, this means a trip to the summer house. After arrival, we concluded that we have too much stuff inside the house, but also an empty wall. We are in Sweden, so the solution, can of course be found at IKEA. The nearest IKEA store is a long boat ride away, so let’s go e-shopping. I know roughly what I would like to buy, so it shouldn’t be difficult, right? In the end, I was able to get a bookcase, but the path was riddled with artificial stupidity - missed opportunities where only slightly more intelligent systems would have smoothened the shopping process, providing value to both customers and to IKEA.
(Clarification added in hindsight: The term “artificial stupidity” refers only to misbehaving machines, as in the examples below, and is not a statement about any human decision making. I place no judgement on the actions of any individual or team. The purpose of this post is merely to shift focus when discussing data-driven products.)
IKEA, I apologise for using you as an example here. It so happens that I am fond of the company and your products. I buy most of my furniture from you, so it is merely one example of interaction with a supplier that was born before the internet, and you happened to provide a suitable narrative. The scenarios below are typical, and representative of my other private service suppliers as well: Skandiabanken, Volvo, Bilia, Trygg-Hansa, etc. I chose to share this story, since it illustrates the discrepancy between the current focus on AI and data science, and what challenges traditional companies need to overcome first.
In each of the artificial stupidity cases mentioned below, the missing functionality is not complex, nor does it involve any AI, machine learning, large scale stream processing or other complicated technical solution. What was missing was either data that needs to propagate from one internal system to another, or information that is easy to compute with simple means. In this article, IKEA receives a bashing, which is completely unfair; they are far better than their direct competitors, and the missed opportunities described below are typical to most mature Scandinavian companies. Meanwhile, the same companies announce new AI strategies and fiercely compete with each other to hire data scientists and machine learning engineers. But these new hires are unlikely to be effectively used unless they arrive in a company that already masters the foundations of data processing, which Monica Rogati eloquently described in the AI hierarchy of needs.
My search for a bookcase starts on ikea.com, where I navigate to the bookcase section, in the hope to get an overview of the different series. I find instead a listing of all 257 bookcase products, including accessories, such as hinges and extra shelves. The full listing not give me an overview, however, and I do not find anything useful.
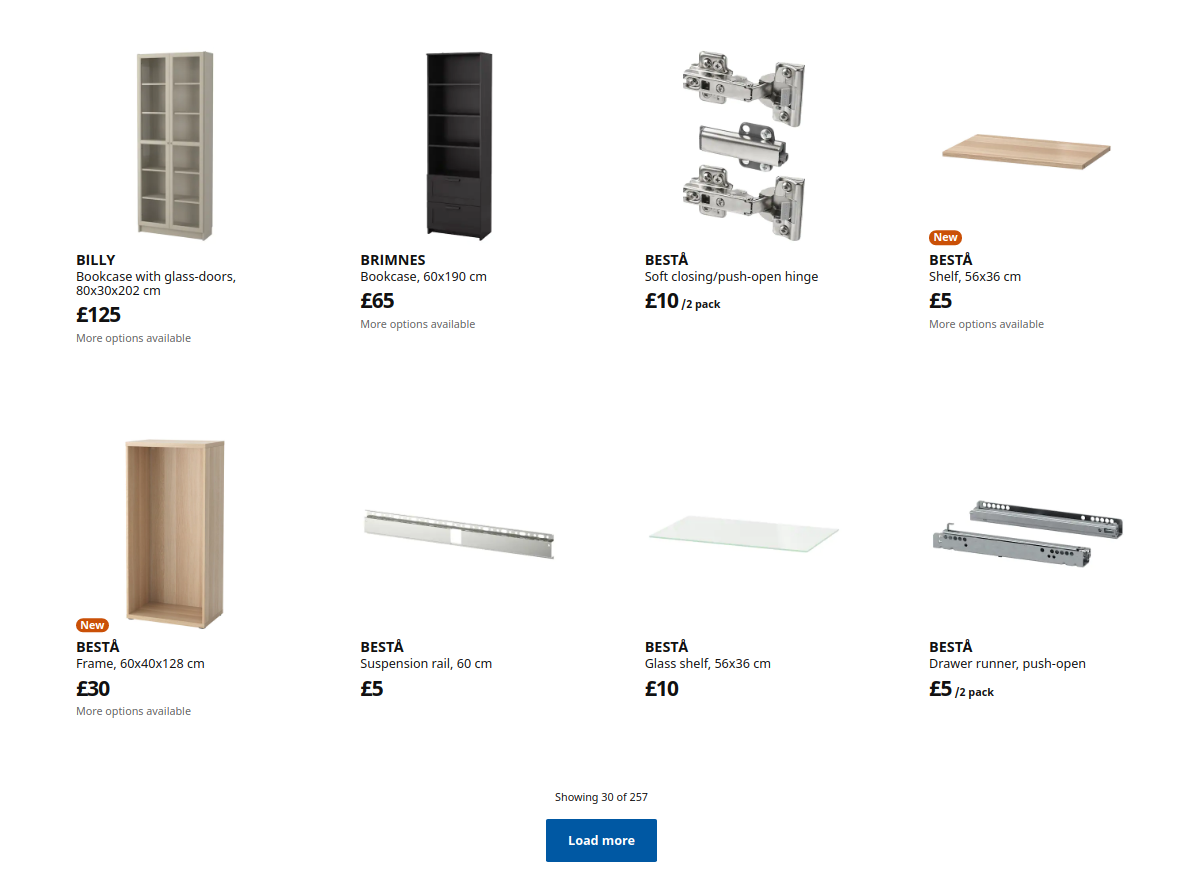
Looking for bookcases
I went to the Swedish site, but some screenshots are from the UK site for the benefit of non-Scandinavian readers.
An impatient customer could have given up at this stage, but I persist and pursue other paths, as described below. I am probably not alone trying this path, giving up, and moving on to another strategy, or leaving the site completely. There are ways to address lost customers, such as user journey mapping - analysing the paths that users take during their interactions with a site, looking for common anomalous patterns. It requires the capability to collect user behavioural data, connecting the data points to aggregations of user journeys, and present it in a actionable format. It involves multiple systems and teams, and getting data to flow between them. It does not, however, require any advanced computations or machine learning.
I move on to a source of product information that I have known since I was a child. The IKEA catalogue is a masterpiece of 20th century product marketing, and a mere glance will make anyone enchanted and filled with desire to furnish a home. I cannot see IKEA’s full bookcase offering here, but I get inspired and find something similar to what I want - the classic series “Ivar”, which is suitably rustique for a 1970’s Scandinavian summer house. The catalogue does not contain an Ivar model of appropriate size, so I try clicking in order to get to the Ivar web pages. But the catalogue is essentially a series of jpegs embedded in a web page, without any hyperlinks - another example of data not properly flowing from one system to another. I am convinced that the team creating the web catalogue would have been able to add hyperlinks, if they only had access to product identifiers from the team in control over the catalogue contents, as well as a reliable map from product identifiers to URLs.

I go back to the web product directory. I enter “Ivar” in the search box, and get 101 results back, in what seems to me like an arbitrary order. There are no bookcases in the first screen of items, mostly accessories and matching chairs.
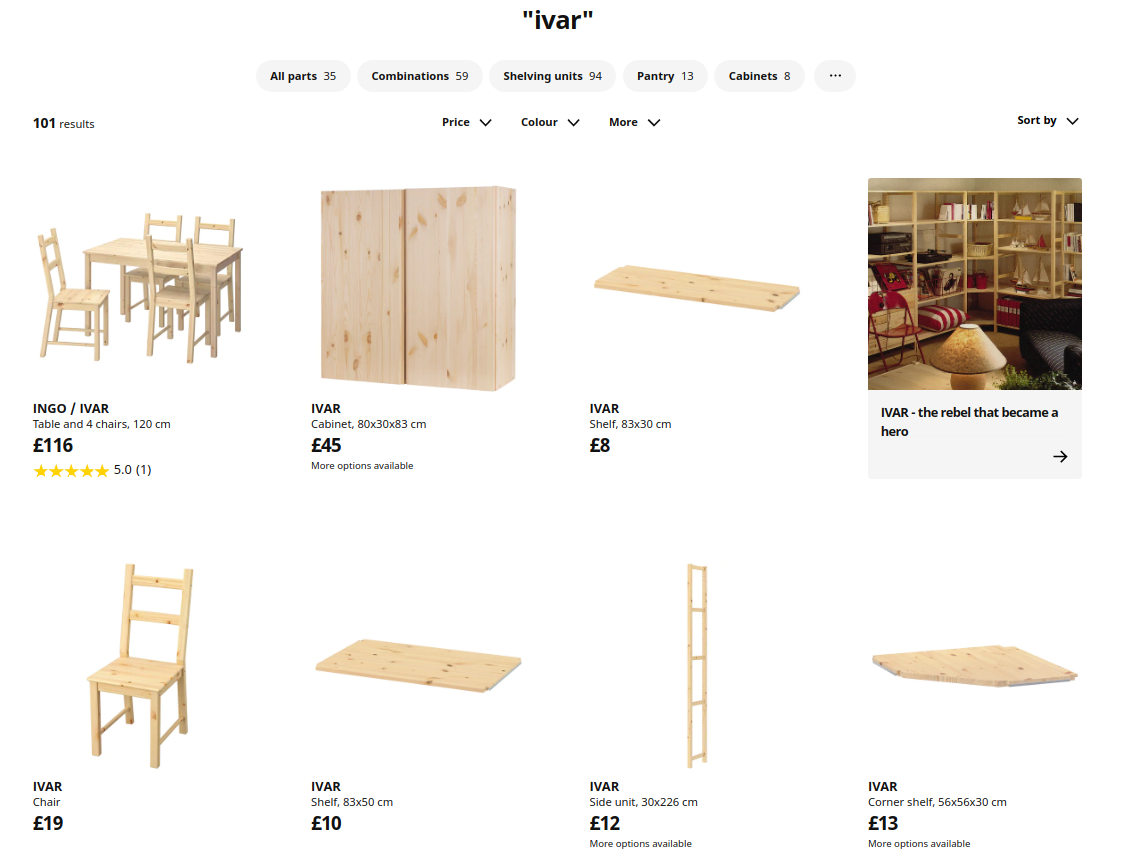
The search result page gives me the option to specify sort order, which is “best match” by default. I ask for the items to be sorted by descending price, and find the large Ivar variants that I am looking for. Sorting by price worked in my case, since I was looking for one of the largest bookcase combinations. Had I been looking for one of the more common bookcases, however, I would have spent more time searching. In that case, it would have been more helpful if the search results had been sorted by popularity. But in order to measure and rank results by popularity, data needs to flow from the web and checkout systems, where it can be collected, to the search indexing and ranking system.
Personalisation is a popular subject these days, and recommendation systems have become common as well as complex. This use case might seem like a good candidate for some personalisation AI. Furniture are infrequently bought items, however, so it is difficult to obtain a good user profile. Imagine the clickbait that some heavily personalised popular applications would present if they knew you were looking for bookcases:
- Amazon: “You must be a bookcase collector! I will suggest bookcases for the next three months.”
- Instagram: “50 crazy ways to pimp your bookcase.”
- Facebook: “Provocative racist bookcases that will make you angry.”
- Youtube: “Spectacular failures while putting up a bookcase.”
For furniture shopping, simple data-driven ranking would serve us better than a complex and fancy algorithm.
I put Ivar in my virtual basket, and log in to IKEAs “My profile”, where personal information, such as home address and IKEA Family bonus club number, is already stored. I proceed to check whether Ivar is in stock (“I lager” in Swedish), since I would prefer to pick it up at a store in order to quickly get my hands on it. Since I have saved my home address to my profile, and I make most of my IKEA shopping at the nearest IKEA store, “Stockholm Barkarby”, I expect that store to be selected as default. But this data is not propagated to the web shop, so I have to select the store that I am interested in.
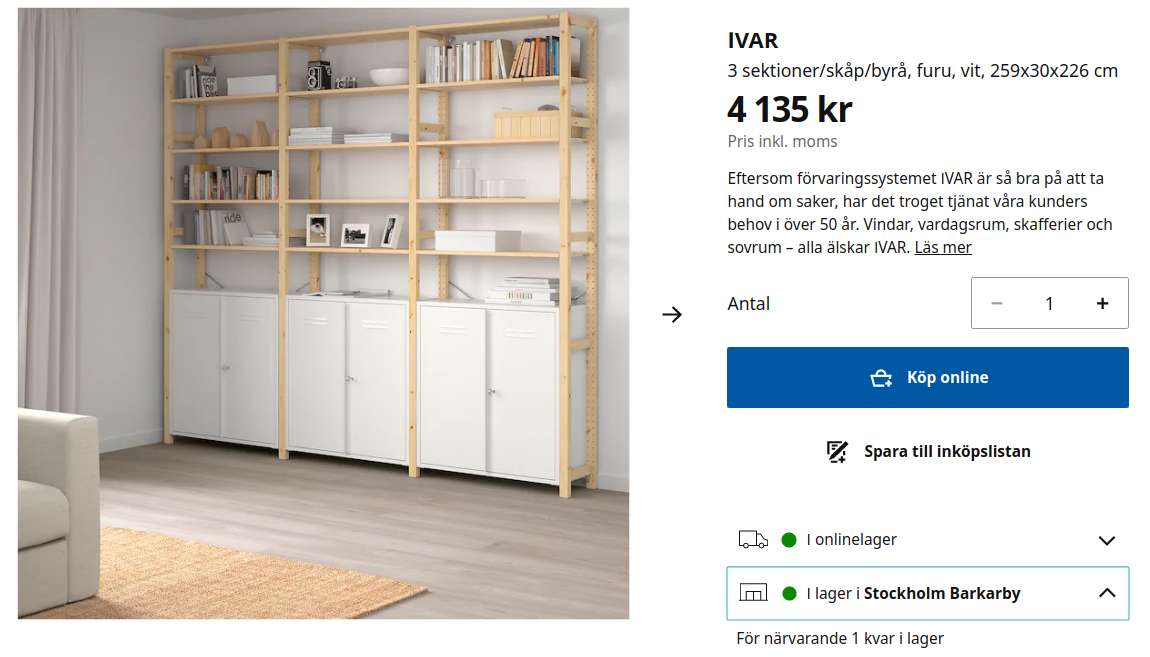
There is one item in stock at the store, great. I proceed to checkout, where I need to fill in my zip code (“postnummer”), even though it is already present in my profile. But it is not readily available to the team and the system that handles the checkout.
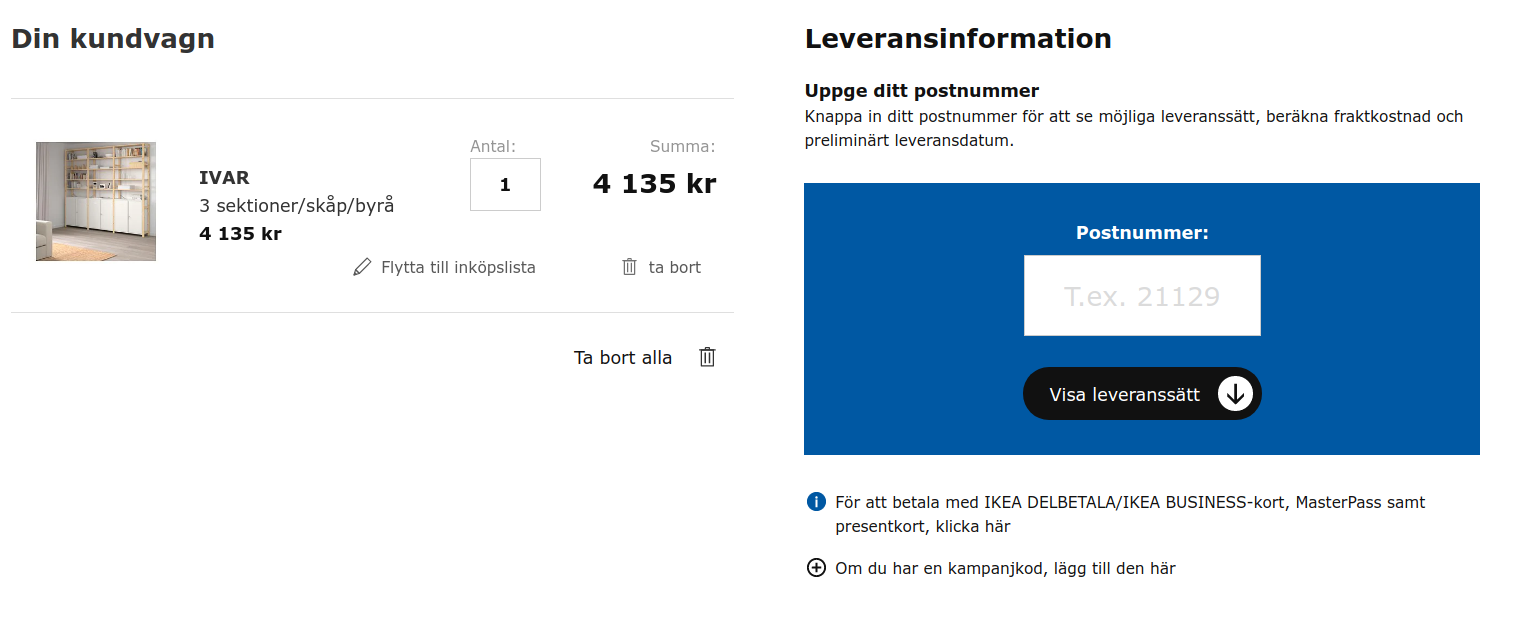
I select “pickup at store”, and the page requests me to pick a store, even though I selected a store of interest above. Again, data not flowing where it could. When I bring up the list of stores, “Stockholm Barkarby” cannot be found. Instead, I find “IKEA Barkarby”.
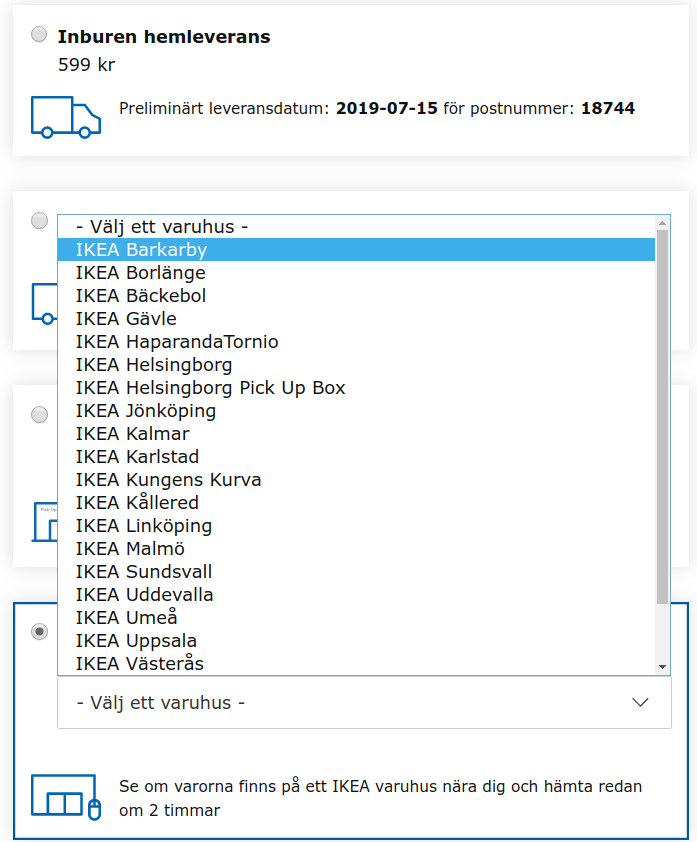
This is an example of inadequate master data management - a process where a combination of data collection, automated processing, and manual curation produces a consistent dataset for important business entities, such as products and stores. For most companies, master data management does not need to be a complex process, merely centralisation of data, combined with resolution of conflicting data based on simple heuristics or manual overrides.
I select the Barkarby store and proceed to checkout. A popup asks me for my IKEA Family number, which should already be known to the web store, since I am logged in. But the data is not propagating between the systems.
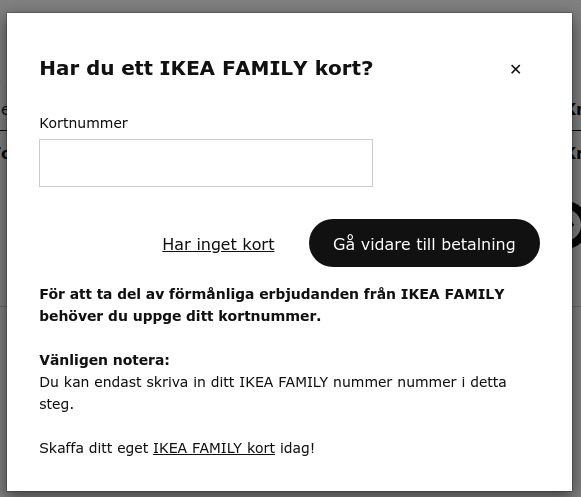
I copy and paste my IKEA Family number from the “My profile” page, and go to the payment page, where I (of course) have to fill in my home address before getting to the final step where I enter my credit card number.
We go to the store in Barkarby, and get assistance from a junior family member to find a few other items in addition to our precious Ivar. Shortly thereafter, our Volvo is fully loaded with flat-packs, and headed for the marina for further transport by boat.

Shopping list, junior edition
In almost every interaction in my shopping path, IKEA could have used data to improve my experience and lowered buying friction. We know that shoppers have little patience, and that any friction in the process means lost customers, so there is revenue at stake. IKEA is probably not at any immediate risk of being disrupted, but companies in other verticals are, and the digital experience with most traditional companies is similar.
While traditional companies strive to do “AI transformations” and rapidly hire data scientists, there are many opportunities to elevate product value by straightforward, unimpressive data solutions - propagating the data to the right place, and automating well understood processes. In no case mentioned in the shopping journey above would machine learning, data science, or anything resembling AI have been necessary in order to provide a pleasant user experience. For most companies, and in most cases, the key to extracting business value from data does not lie in machine learning, nor in handling large data volumes, but in data democratisation - making data accessible within the company, and making it easy to process and use for decisions or for building data-driven features. AI solutions feed on data, and one cannot expect a company to be transformed by AI nor data-driven unless data can flow without friction from one end of the organisation to another. The data scientists that everyone is hiring cannot help a company become data democratised; it is a joint collaboration between product managers, data engineers, and managers or coaches that can break down organisational silos where data is locked up. Mastering the foundations of data engineering and data democratisation is a necessary prerequisite for building sustainable machine learning products. Any transformation towards artificial intelligence must start by avoiding artificial stupidity.
